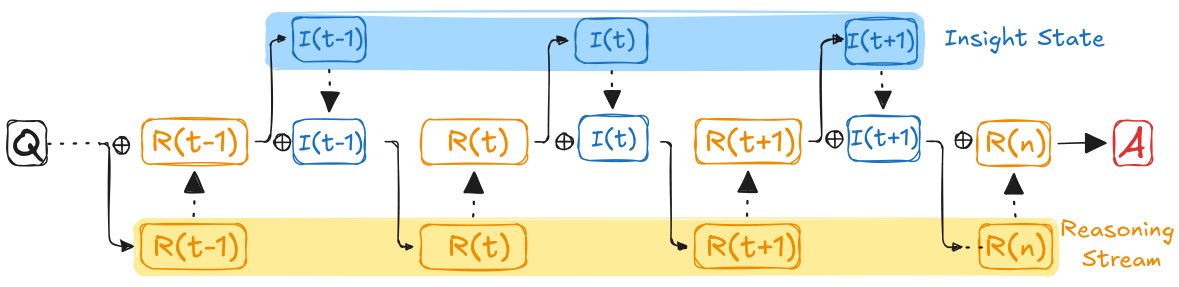
Motivation
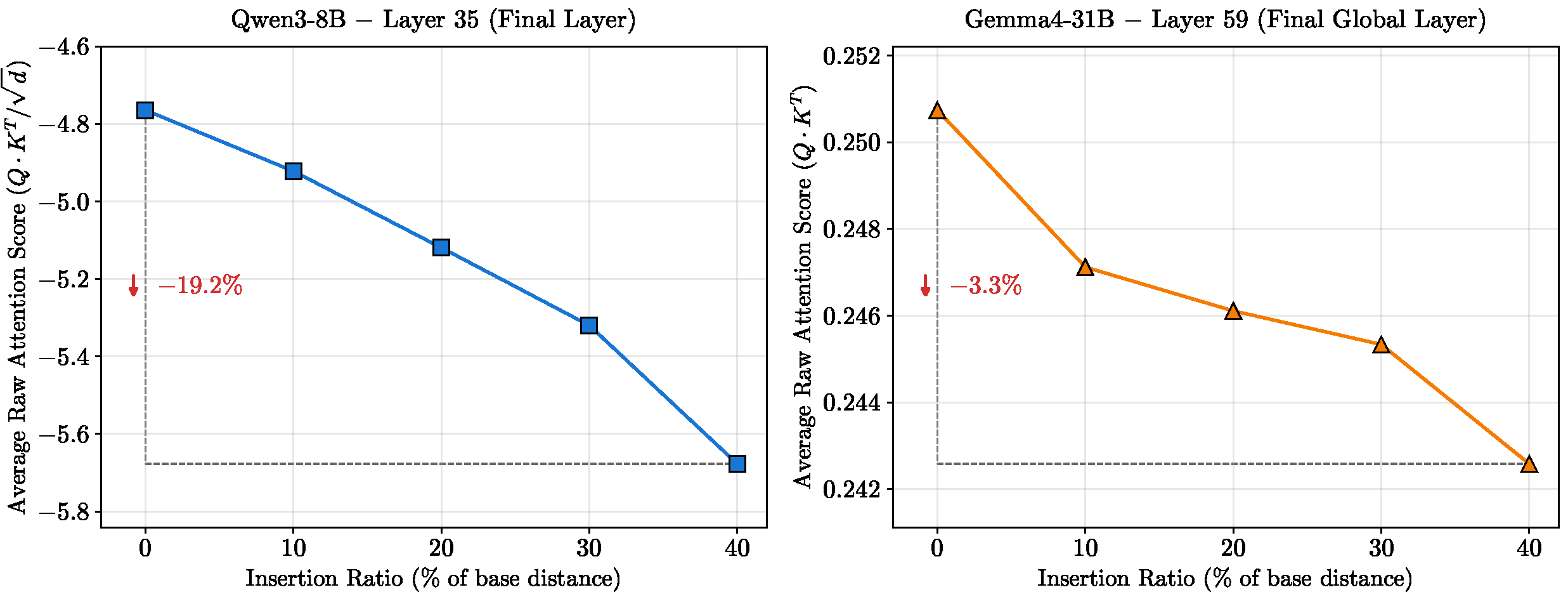
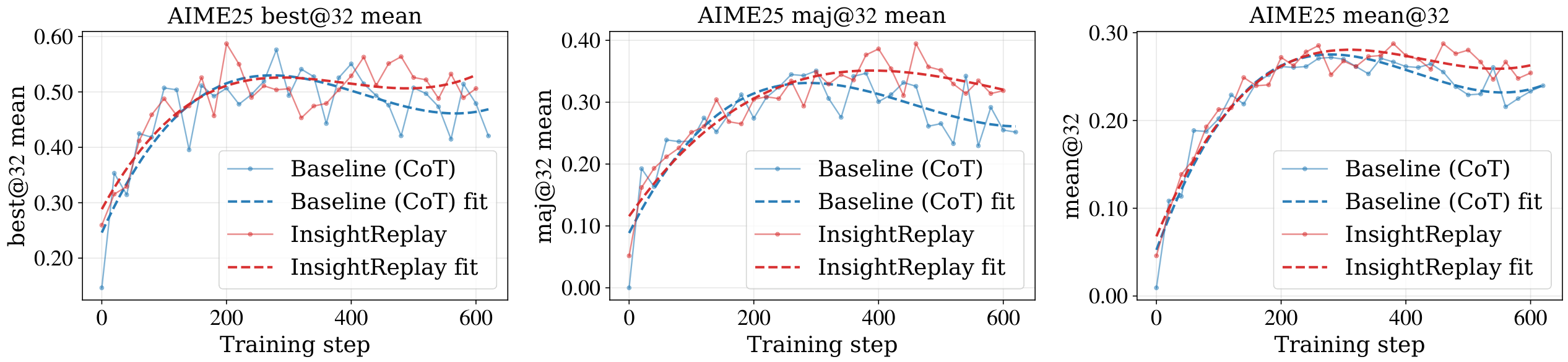
Recent work shows that longer chain-of-thought (CoT) is not monotonically better. On a fixed-difficulty problem, accuracy traces an inverted-U as CoT length grows — first improving, peaking, then declining as the chain becomes excessively long. We ask: what drives this decline, and can it be fixed?
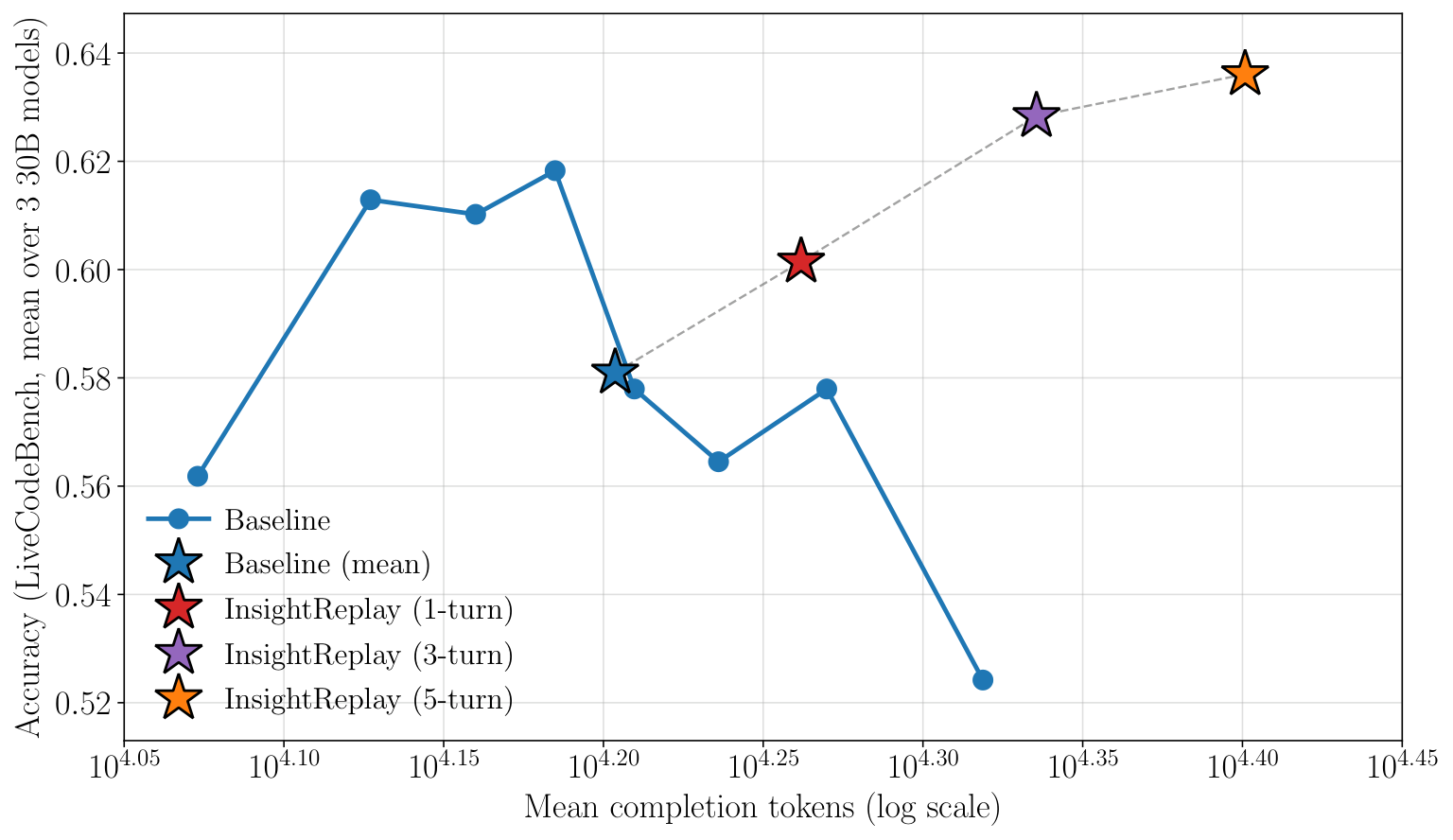
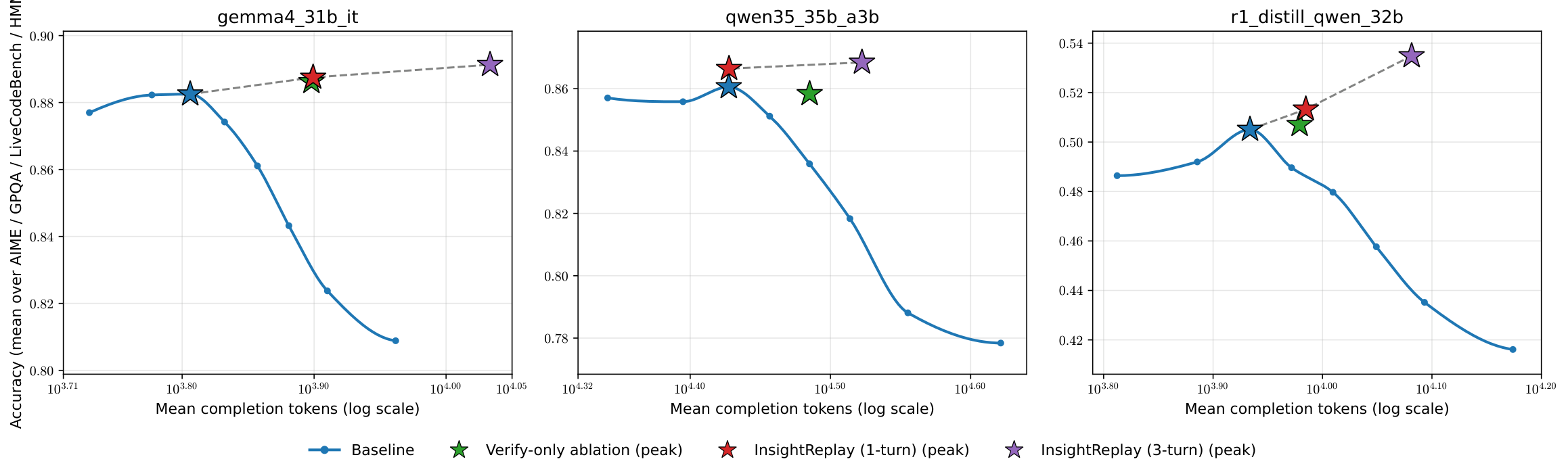
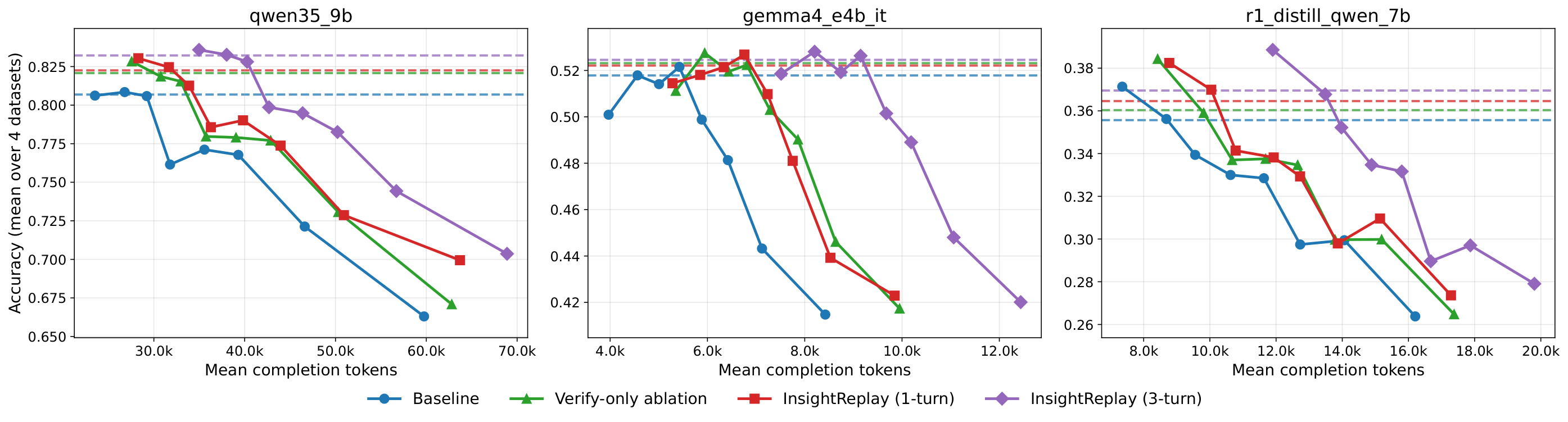
Accuracy vs. mean tokens for Baseline (standard CoT) and InsightReplay (1, 3, 5 replay rounds), averaged over three 30B-tier models on the LiveCodeBench v5 subset. Baseline peaks at ~15K tokens then declines; InsightReplay turns the degradation regime into continued growth.